- Published on
Spring 扫描原理(核心重点)
Spring 执行扫描的时机
spring容器初始化的时候执行invokeBeanFactoryPostProcessors方法内部执行内置的BeanDefinitionRegistryPostProcessor的时候调用ConfigurationClassPostProcessor的postProcessBeanDefinitionRegistry的时候完成了扫描;当然这个方法不仅仅完成了扫描。
模拟扫描的过程,思路分析
- 根据��包名信息得到一个该包名对应的文件对象(
File) - 获取改文件对象下面所有的文件(非目录,如果是目录可以递归)
file.list() - 遍历这些文件,通过反射
Class.forName得到Class对象 - 解析这个
Class对象,判断是否符合规则 - 如果符合规则便实例化一个
beanDefinition对象 - 继而把这个
beanDefinition对象put到beanDefinitionMap当中
Spring 为什么用ASM
上述方法完成扫描的主要缺点在于通过Class.forName会提前加载一个类;spring觉这样可能影响用户的行为所以在spring底层并没有采用反射加载一个类,而是通过ASM字节码技术注解读取一个类文件的
信息,当然也不排除ASM的效率比较高,但是我觉得这不是主要原因;ASM还能不执行客户端代码编写的静态方法等。
Spring 的两个扫描器
容器对象在实例化的时候构造方法内部会实例化一个扫描器,而后在处理配置类的@ComponentScan注解的时候又实例化了一个扫描器对象
this.scanner = new ClassPathBeanDefinitionScanner(this);//扫描器1
//扫描器2
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry, componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
怎么理解两个扫描器
扫描器1可以通过容器对象直接调用scan方法完成扫描——context.scan("com.xxxx");扫描器2是spring内部自己调用,是一个方法的局部变量,程序员无法手动调用他;扫描器1可配置信息比较少——执行名字生成器配置;扫描器2支持的配置比较丰富,可以通过配置类上的@ComponentScan注解进行自定义的配置;
为什么要两个扫描器?
扫描器1的存在可以理解作为扫描器2的一个补充;可以让我们通过编程方式调用api完成扫描;那么为什么扫描器2需要重写new?因为如果不重新new是无法重写初始化、或者说无法重写配置;因为扫描器1的实例化时机在容器构造方法内;那时候配置类还没有解析;那么无法获取我们配置的信息;所以不能做初始化。
Spring 扫描流程 通过源码分析可知
- 实例化扫描器、初始化扫描器,初始化的时候默认注册了三个
include过滤器 spring解析@ComponentScan注解得到包名- 根据包名扫描出来改包下面的所有的文件(spring用了一个
Resource来描述文件) - 遍历这些文件,通过ASM字节码技术读取这些文件信息,封装成为一个
metadataReader对象 - 第一次调用
isCandidateComponent,通过metadataReader对象的信息判断是否排除、是否include - 如果被
include则实例化ScannedGenericBeanDefinition对象 - 判断
ScannedGenericBeanDefinition是否接口是否抽象、是否加了`LockUp``注解等等 - 如果正常则
put到beanDefinitionMap
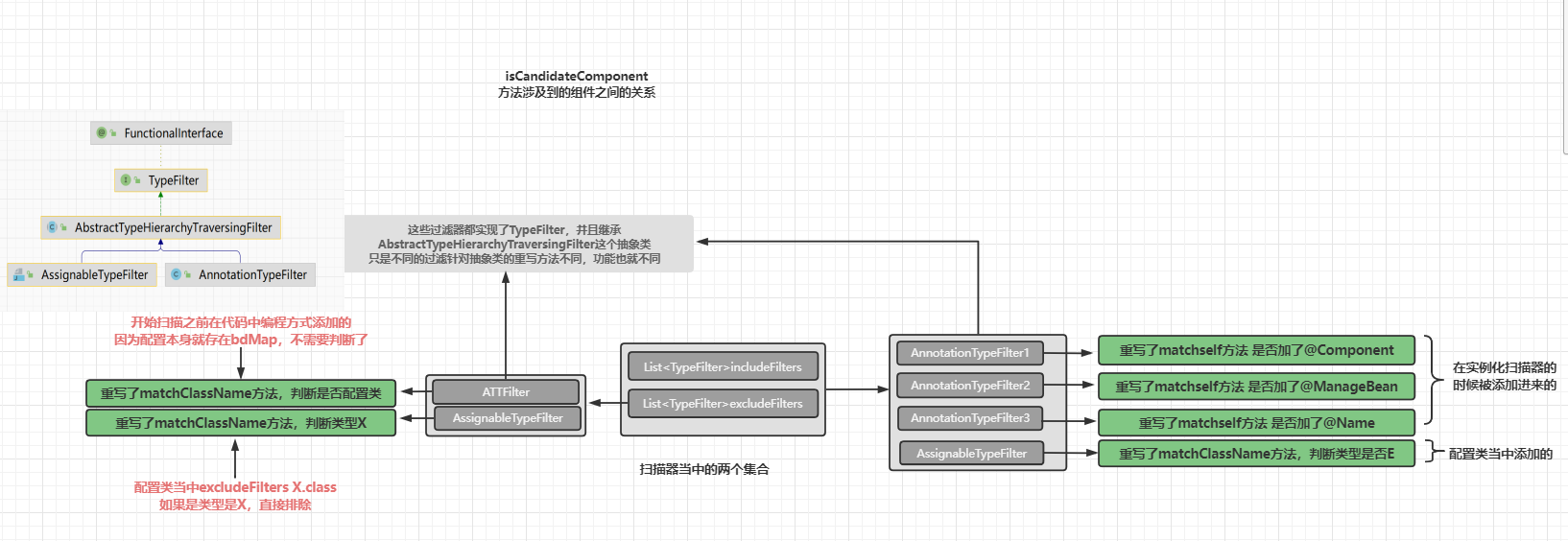
排除过滤器
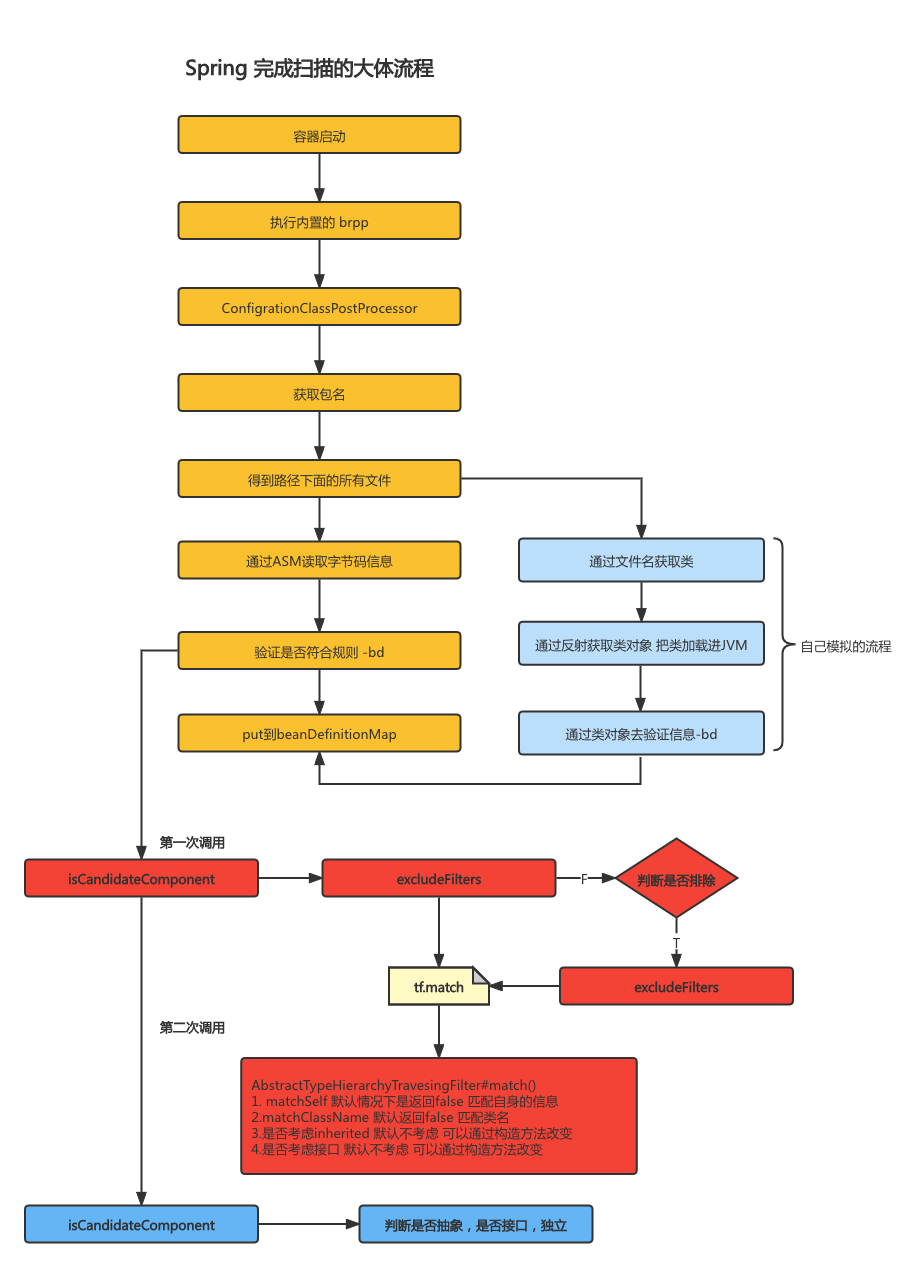
include 过滤器
关于@Inherited
- 类继承关系中@Inherited的作用
- 子类会继承父类使用的注解中被@Inherited修饰的注解
- 接口继承关系中@Inherited的作用
- 子接口不会继承父接口中的任何注解,不管父接口中使用的注解有没有被@Inherited修饰
- 类实现接口关系中@Inherited的作用
- 类实现接口时不会继承任何接口中定义的注解
元数据
元数据,是框架设计中必须的一个概念,所有的流行框架里都能看到它的影子,包括且不限于Spring、SpringBoot、SpringCloud、MyBatis、Hibernate等。它的作用肯定是大大的,它能模糊掉具体的类型,能让数据输出变得统一,能解决Java抽象解决不了的问题,比如运用得最广的便是注解,因为它不能继承无法抽象,所以用元数据方式就可以完美行成统一的向上抽取让它变得与类型无关,也就是常说的模糊效果,这便是框架的核心设计思想。
不管是ClassMetadata还是AnnotatedTypeMetadata都会有基于反射和基于ASM的两种解决方案,他们能使用于不同的场景:
标准反射:它依赖于Class,优点是实现简单,缺点是使用时必须把Class加载进来。
ASM:无需提前加载Class入JVM,所有特别特别适用于形如Spring应用扫描的场景(扫描所有资源,但并不是加载所有进JVM/容器~)
/**
* @author: wangyj
* @create: 2022-03-08
* @version: 1.0.0
* @link https://fangshixiang.blog.csdn.net/article/details/88765470
**/
@Repository("repositoryName")
@Service("serviceName")
@EnableAsync
class MetaDemo extends HashMap<String, String> implements Serializable {
private static class InnerClass {
}
@Autowired
private String getName() {
return "demo";
}
public static void main(String[] args) throws IOException {
StandardAnnotationMetadata metadata = new StandardAnnotationMetadata(MetaDemo.class, true);
// 演示ClassMetadata的效果
System.out.println("==============ClassMetadata==============");
ClassMetadata classMetadata = metadata;
System.out.println(classMetadata.getClassName()); //com.fsx.maintest.MetaDemo
System.out.println(classMetadata.getEnclosingClassName()); //null 如果自己是内部类此处就有值了
System.out.println(StringUtils.arrayToCommaDelimitedString(classMetadata.getMemberClassNames())); //com.fsx.maintest.MetaDemo$InnerClass 若木有内部类返回空数组[]
System.out.println(StringUtils.arrayToCommaDelimitedString(classMetadata.getInterfaceNames())); // java.io.Serializable
System.out.println(classMetadata.hasSuperClass()); // true(只有Object这里是false)
System.out.println(classMetadata.getSuperClassName()); // java.util.HashMap
System.out.println(classMetadata.isAnnotation()); // false(是否是注解类型的Class,这里显然是false)
System.out.println(classMetadata.isFinal()); // false
System.out.println(classMetadata.isIndependent()); // true(top class或者static inner class,就是独立可new的)
// 演示AnnotatedTypeMetadata的效果
System.out.println("==============AnnotatedTypeMetadata==============");
AnnotatedTypeMetadata annotatedTypeMetadata = metadata;
System.out.println(annotatedTypeMetadata.isAnnotated(Service.class.getName())); // true(依赖的AnnotatedElementUtils.isAnnotated这个方法)
System.out.println(annotatedTypeMetadata.isAnnotated(Component.class.getName())); // true
System.out.println(annotatedTypeMetadata.getAnnotationAttributes(Service.class.getName())); //{value=serviceName}
System.out.println(annotatedTypeMetadata.getAnnotationAttributes(Component.class.getName())); // {value=repositoryName}(@Repository的value值覆盖了@Service的)
System.out.println(annotatedTypeMetadata.getAnnotationAttributes(EnableAsync.class.getName())); // {order=2147483647, annotation=interface java.lang.annotation.Annotation, proxyTargetClass=false, mode=PROXY}
// 看看getAll的区别:value都是数组的形式
System.out.println(annotatedTypeMetadata.getAllAnnotationAttributes(Service.class.getName())); // {value=[serviceName]}
System.out.println(annotatedTypeMetadata.getAllAnnotationAttributes(Component.class.getName())); // {value=[, ]} --> 两个Component的value值都拿到了,只是都是空串而已
System.out.println(annotatedTypeMetadata.getAllAnnotationAttributes(EnableAsync.class.getName())); //{order=[2147483647], annotation=[interface java.lang.annotation.Annotation], proxyTargetClass=[false], mode=[PROXY]}
// 演示AnnotationMetadata子接口的效果(重要)
System.out.println("==============AnnotationMetadata==============");
AnnotationMetadata annotationMetadata = metadata;
System.out.println(annotationMetadata.getAnnotationTypes()); // [org.springframework.stereotype.Repository, org.springframework.stereotype.Service, org.springframework.scheduling.annotation.EnableAsync]
System.out.println(annotationMetadata.getMetaAnnotationTypes(Service.class.getName())); // [org.springframework.stereotype.Component, org.springframework.stereotype.Indexed]
System.out.println(annotationMetadata.getMetaAnnotationTypes(Component.class.getName())); // [](meta就是获取注解上面的注解,会排除掉java.lang这些注解们)
System.out.println(annotationMetadata.hasAnnotation(Service.class.getName())); // true
System.out.println(annotationMetadata.hasAnnotation(Component.class.getName())); // false(注意这里返回的是false)
System.out.println(annotationMetadata.hasMetaAnnotation(Service.class.getName())); // false(注意这一组的结果和上面相反,因为它看的是meta)
System.out.println(annotationMetadata.hasMetaAnnotation(Component.class.getName())); // true
System.out.println(annotationMetadata.hasAnnotatedMethods(Autowired.class.getName())); // true
annotationMetadata.getAnnotatedMethods(Autowired.class.getName()).forEach(methodMetadata -> {
System.out.println(methodMetadata.getClass()); // class org.springframework.core.type.StandardMethodMetadata
System.out.println(methodMetadata.getMethodName()); // getName
System.out.println(methodMetadata.getReturnTypeName()); // java.lang.String
});
// ********** 像这些元数据,在框架设计时候很多时候我们都希望从File(Resource)里得到,而不是从Class文件里获取,所以就是MetadataReader和MetadataReaderFactory **********
CachingMetadataReaderFactory readerFactory = new CachingMetadataReaderFactory();
// 下面两种初始化方式都可,效果一样
//MetadataReader metadataReader = readerFactory.getMetadataReader(MetaDemo.class.getName());
MetadataReader metadataReader = readerFactory.getMetadataReader(new ClassPathResource("jinggo/spring/example/batMan/spring/MetaDemo.class"));
ClassMetadata classMetadata2 = metadataReader.getClassMetadata();
AnnotationMetadata annotationMetadata2 = metadataReader.getAnnotationMetadata();
Resource resource = metadataReader.getResource();
System.out.println(classMetadata2); // org.springframework.core.type.classreading.AnnotationMetadataReadingVisitor@79079097
System.out.println(annotationMetadata2); // org.springframework.core.type.classreading.AnnotationMetadataReadingVisitor@79079097
System.out.println(resource); // class path resource [com/fsx/maintest/MetaDemo.class]
}
}